In the last months I gave several times this talk about my recent work on knowledge transfer for large-scale visual recognition problems (e.g. Aquifi Inc – Palo Alto, Google Research, UC Santa Cruz, MICC, U. of Parma, U. of Catania, U. of Padova, “Ca’ Foscari” U. Venice). The key idea of our work is to transfer prior contextual knowledge to novel scenes where it is hard to collect large-scale training data [slides available online].
 I have been selected Marie Curie Fellow of the week! Marie Sklodowska-Curie Actions (MSCA) Individual Fellowships are highly prestigious and competitive and are meant to support the best, most promising European researchers.
I have been selected Marie Curie Fellow of the week! Marie Sklodowska-Curie Actions (MSCA) Individual Fellowships are highly prestigious and competitive and are meant to support the best, most promising European researchers.
More info on this Facebook post.
 I am co-organizing a special issue for the Computer Vision and Image Understanding journal on “Computer Vision and the Web”, together with Shih-Fu Chang (Columbia University), Gang Hua (Microsoft Research Asia), Thomas Mensink (Univ. of Amsterdam), Greg Mori (Simon Fraser Univ.) and Rahul Sukthankar (Google Research). You can see all the details on the call for papers.
I am co-organizing a special issue for the Computer Vision and Image Understanding journal on “Computer Vision and the Web”, together with Shih-Fu Chang (Columbia University), Gang Hua (Microsoft Research Asia), Thomas Mensink (Univ. of Amsterdam), Greg Mori (Simon Fraser Univ.) and Rahul Sukthankar (Google Research). You can see all the details on the call for papers.
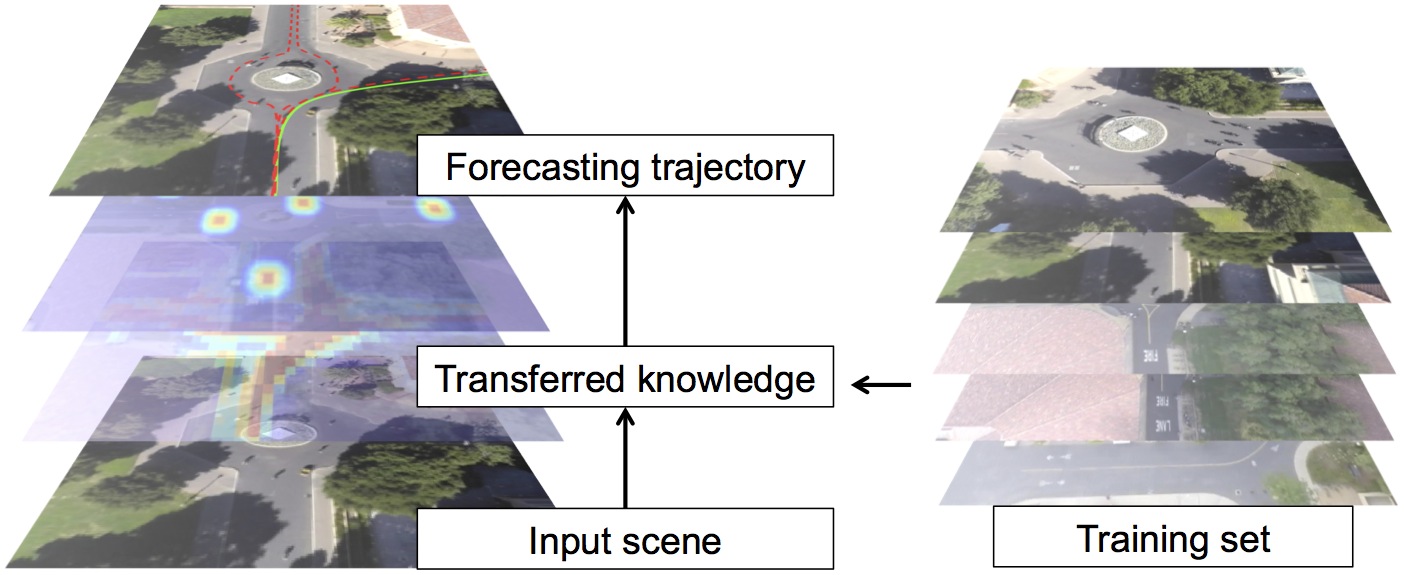
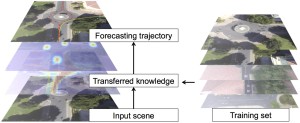 Our paper “Knowledge Transfer for Scene-specific Motion Prediction”, by L. Ballan, F. Castaldo, A. Alahi, F. Palmieri and S. Savarese, has been accepted to ECCV 2016. A pre-print is available on arXiv.
Our paper “Knowledge Transfer for Scene-specific Motion Prediction”, by L. Ballan, F. Castaldo, A. Alahi, F. Palmieri and S. Savarese, has been accepted to ECCV 2016. A pre-print is available on arXiv.
When given a single frame of the video, humans can not only interpret the content of the scene, but also they are able to forecast the near future. This ability is mostly driven by their rich prior knowledge about the visual world, both in terms of (i) the dynamics of moving agents, as well as (ii) the semantic of the scene. We exploit the interplay between these two key elements to predict scene-specific motion patterns.
 In the past two weeks I have been involved as computer vision project mentor in the Stanford Artificial Intelligence Laboratory’s OutReach Summer program (SAILORS). SAILORS is a summer camp for high school girls and it is intended to increase diversity in the field of AI. SAILORS aims to teach technically rigorous AI concepts in the context of societal impact.
In the past two weeks I have been involved as computer vision project mentor in the Stanford Artificial Intelligence Laboratory’s OutReach Summer program (SAILORS). SAILORS is a summer camp for high school girls and it is intended to increase diversity in the field of AI. SAILORS aims to teach technically rigorous AI concepts in the context of societal impact.
Check out SAILORS blog to know more about the program. SAILORS was also recently featured in Wired.
 We gave a tutorial on “Image Tag Assignment, Refinement and Retrieval” at CVPR 2016, based on our survey. The focus is on challenges and solutions for content-based image retrieval in the context of online image sharing. We present a unified review on three problems: tag assignment, refinement, and tag-based image retrieval.
We gave a tutorial on “Image Tag Assignment, Refinement and Retrieval” at CVPR 2016, based on our survey. The focus is on challenges and solutions for content-based image retrieval in the context of online image sharing. We present a unified review on three problems: tag assignment, refinement, and tag-based image retrieval.
The slides are available on this page.
I am co-organizing the 4th Int’l Workshop on Web-scale Vision and Social Media (VSM) at ECCV 2016, with Marco Bertini (Univ. Florence, Italy) and Thomas Mensink (Univ. Amsterdam, NL).
Website: https://sites.google.com/site/vsm2016eccv/
Vision and social media has recently become a very active inter-disciplinary research area, involving computer vision, multimedia, machine learning, and data mining. This workshop aims to bring together researchers in the related fields to promote new research directions for problems involving vision and social media, such as large-scale visual content analysis, search and mining.
 Everything you wanted to know about image tagging, tag refinement and social image retrieval. Our paper has been (finally) accepted to ACM Computing Surveys! This is a titanic effort, by Xirong Li, Tiberio Uricchio, myself, Marco Bertini, Cees Snoek and Alberto Del Bimbo, to structure the growing literature in the field, understand the ingredients of the main works, clarify their connections and difference, and recognize their merits and limitations.
Everything you wanted to know about image tagging, tag refinement and social image retrieval. Our paper has been (finally) accepted to ACM Computing Surveys! This is a titanic effort, by Xirong Li, Tiberio Uricchio, myself, Marco Bertini, Cees Snoek and Alberto Del Bimbo, to structure the growing literature in the field, understand the ingredients of the main works, clarify their connections and difference, and recognize their merits and limitations.
A pre-print is available on arXiv and the source code is on GitHub.
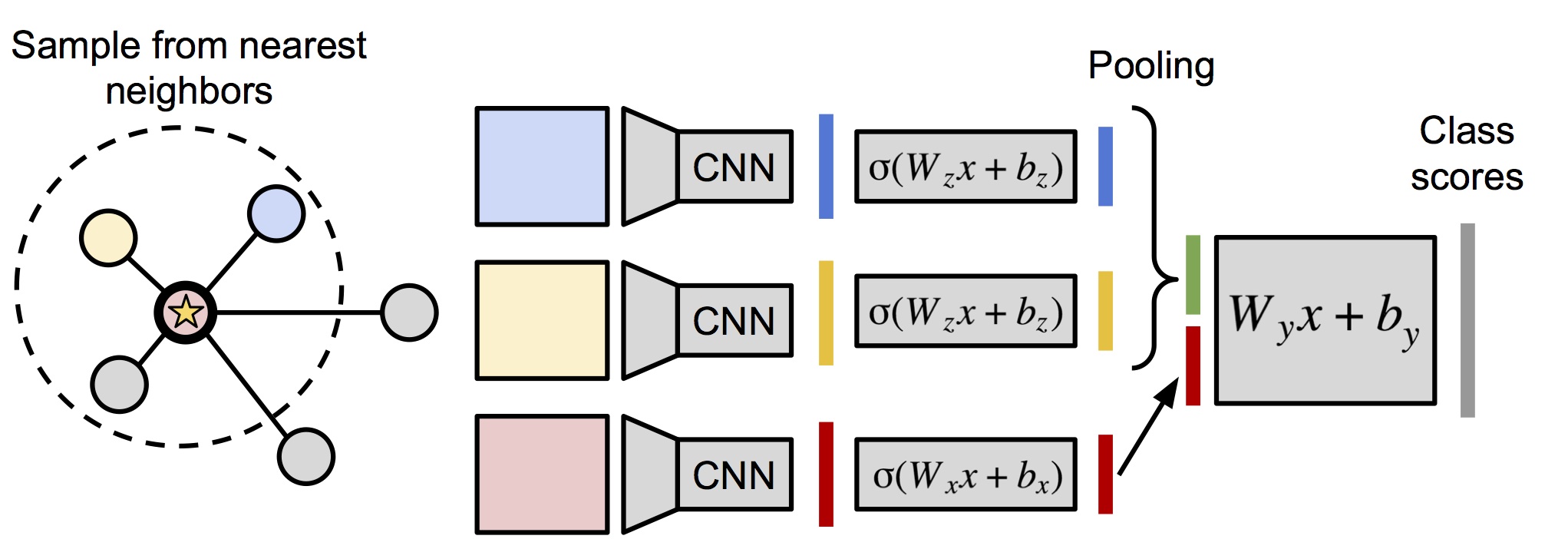
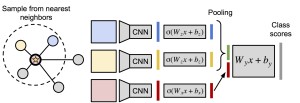 Our paper “Love Thy Neighbors: Image Annotation by Exploiting Image Metadata”, by J. Johnson*, L. Ballan* and L. Fei-Fei (* equal contribution), has been accepted to ICCV 2015. A pre-print is now available on arXiv.
Our paper “Love Thy Neighbors: Image Annotation by Exploiting Image Metadata”, by J. Johnson*, L. Ballan* and L. Fei-Fei (* equal contribution), has been accepted to ICCV 2015. A pre-print is now available on arXiv.
Some images that are difficult to recognize on their own may become more clear in the context of a neighborhood of related images with similar social-network metadata. We build on this intuition to improve multilabel image annotation. Our model uses image metadata nonparametrically to generate neighborhoods of related images using Jaccard similarities, then uses a deep neural network to blend visual information from the image and its neighbors.
 We gave a tutorial on “Image Tag Assignment, Refinement and Retrieval” at ACM MM 2015, based on our recent survey. Our tutorial focuses on challenges and solutions for content-based image retrieval in the context of online image sharing and tagging. We present a unified review on three closely linked problems: tag assignment, tag refinement, and tag-based image retrieval. We introduce a taxonomy to structure the growing literature, understand the ingredients of the main works, and recognize their merits and limitations.
We gave a tutorial on “Image Tag Assignment, Refinement and Retrieval” at ACM MM 2015, based on our recent survey. Our tutorial focuses on challenges and solutions for content-based image retrieval in the context of online image sharing and tagging. We present a unified review on three closely linked problems: tag assignment, tag refinement, and tag-based image retrieval. We introduce a taxonomy to structure the growing literature, understand the ingredients of the main works, and recognize their merits and limitations.
We provided also an hands-on session with the main methods, software and datasets. All data, code and slides are online at: http://www.micc.unifi.it/tagsurvey